SEO  Block unuseful pages
Block unuseful pages

The full text of this guideline states:
"Use robots.txt to prevent crawling of search results pages or other auto-generated pages that don't add much value for users coming from search engines".
Search result pages on your site are a clear example of this. Every time someone searches your website they are provided a search results page. If these pages are not blocked from Google then you may end up having massive duplicate content problems that may undermine your good standing in Google.
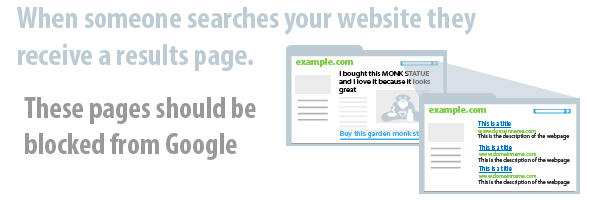
To illustrate this let's say you have a website that only has five pages. You also have a search function that helps users find what they need. When your users perform a search of your website, a search result page is created.
If these pages are not blocked from Google, then your five page website can become a thousand page website as far as Google is concerned.

This occurs because every search result page can be indexed by Google if it is not blocked. The end result is that instead of having a five page website that is laser focused on your subject, Google now thinks you are a thousand page website that isn't very focused on anything at all.
This makes Google rank you lower as it no longer sees you as a valuable site, even though you are.
How to Determine which pages to block
Search result pages are not the only pages to block in many websites. Often a website can have pages that are auto generated or mostly auto generated which need to be blocked as well.
Poor rankings in Google often occur because websites are not providing unique content, so it makes good sense to block the pages of your websites that are not unique or are mostly not unique.
Another specific example of content that should be blocked are pages created primarily from affiliate databases, or any information that is not coming from you, but is being generated somehow for you from other sources.
Google sees no value in indexing or ranking pages which are not original, useful content. Users hate to go to pages that have the same exact information as other webpages, so Google hates it too.
On this website, I have online tools to help webmasters, many of those tools provide a result page and I have taken measures via my robots.txt file and through robots directives to ensure that those result pages do not end up in the Google index.
How to block pages via robots.txt
One of the Google webmaster guidelines tells us to "make use of the robots.txt file on your web server", and here is one place we can do that. Blocking pages via this file can be done in a couple ways. If you are not familiar with robots.txt file, you may want to read the linked article above first. If you are familiar already with how a robots.txt file works you can...
- Blocking folders - The most simple way to block content is by folder. If you have content you wish to block, you can arrange it into one folder and block that entire folder: Disallow: /searchresults/
- Wildcards - If all of your search results or other content you wish blocked are generated dynamically, the results may have an indicator in the url such as a question mark "?" in the url. If you entire website is static, but you provide search results or tool results dynamically, an easy way to block this content is to use a wildcard: Disallow: /*?*
 by Patrick Sexton
by Patrick Sexton
